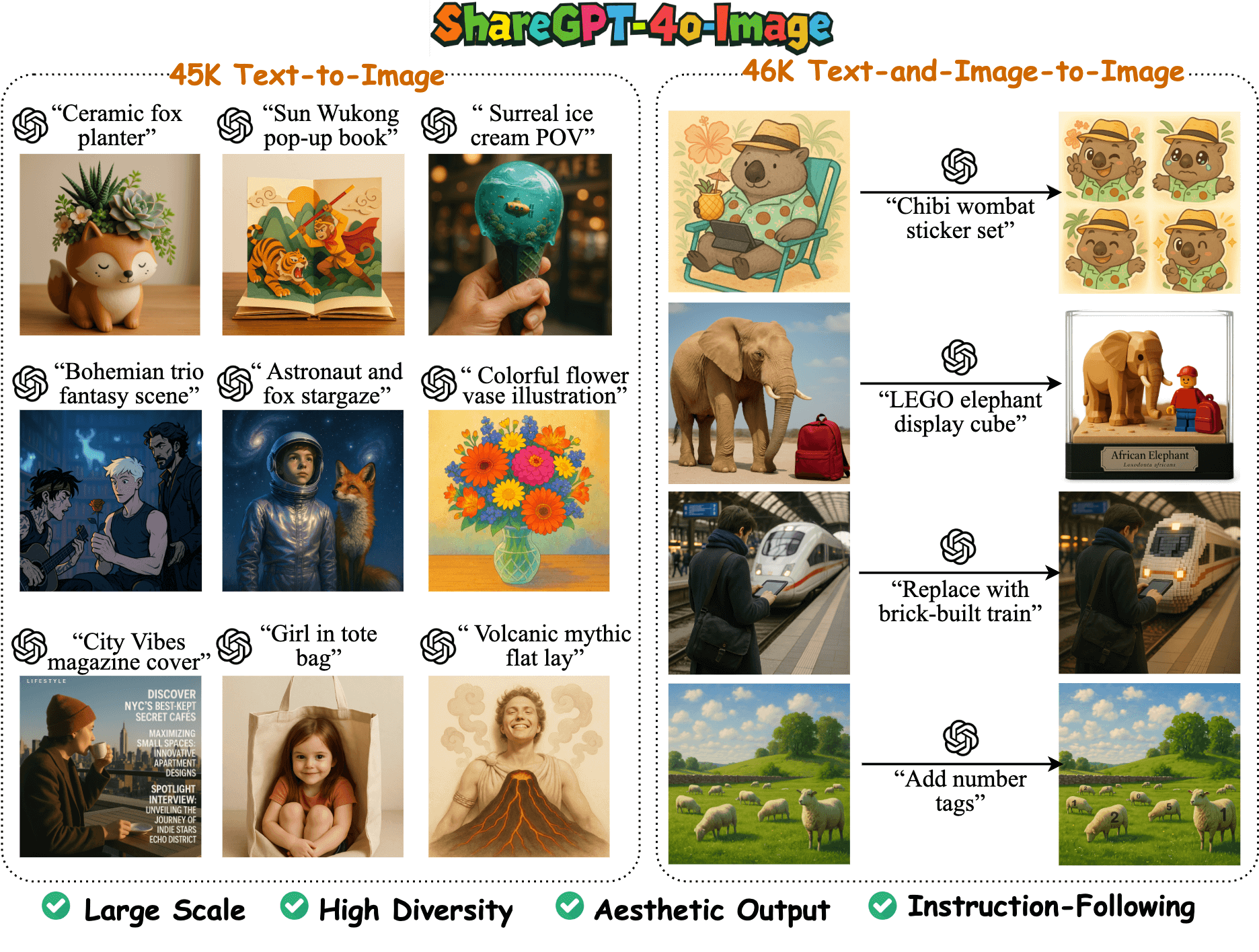GPT-Image-Edit
综合介绍
GPT-Image-Edit 是一个开源项目,它提供了一个包含150万个样本的大规模图像编辑数据集,以及一个基于该数据集训练的先进AI图像编辑模型。该项目的目标是推动开源社区在指令驱动的图像编辑领域的发展,缩小与顶级闭源模型之间的差距。 项目利用GPT-4o的能力,对现有的多个图像编辑数据集(如OmniEdit, HQ-Edit, 和 UltraEdit)进行整合与优化,通过重新生成图像和改写文本指令,显著提升了数据的整体质量和指令的清晰度。 用户可以使用这个项目提供的代码和模型,通过简单的文本指令对图像进行各种编辑,项目也支持开发者基于其发布的数据集进行模型的再训练和评估。
功能列表
- 大规模数据集:提供一个包含超过150万个“指令、源图像、编辑后图像”数据对的高质量数据集
GPT-IMAGE-EDIT-1.5M,用于训练和研究。 - 文本指令编辑:用户可以通过自然语言指令,对图像进行修改,例如改变物体颜色、添加或移除元素、调整背景等。
- 模型训练与评估:项目提供了完整的训练和评估代码,研究人员可以复现模型训练过程,或在标准测试集(如GEdit, ImgEdit, Complex-Edit)上评估模型性能。
- 多种运行方式:支持通过命令行界面(CLI)进行快速测试和脚本化操作。
- Web交互界面:提供基于Gradio的Web用户界面,让不熟悉命令行的用户也能方便地进行可视化操作。
- 模型兼容性:代码基于UniWorld-V1框架,并集成了FLUX.1和Qwen2.5-VL等先进的视觉语言模型。
使用帮助
GPT-Image-Edit不仅是一个数据集,也是一个可以实际操作的图像编辑工具。下面将详细介绍如何配置环境、下载模型并运行该工具。
第一步:环境设置
首先,你需要一个已经安装了Conda的环境,以便更好地管理Python依赖。
- 克隆代码库: 打开你的终端(Terminal),使用
git命令将项目文件从GitHub下载到本地。git clone https://github.com/wyhlovecpp/GPT-Image-Edit.git - 进入项目目录:
cd GPT-Image-Edit - 创建并激活Conda环境: 项目建议使用Python 3.10版本。以下命令会创建一个名为
univa的独立环境并激活它。conda create -n univa python=3.10 -y conda activate univa - 安装依赖库: 项目所需的Python库都记录在
requirements.txt文件中。使用pip进行安装。pip install -r requirements.txt pip install flash_attn --no-build-isolation ``` *注:`flash_attn`是一个用于提升Transformer模型效率的库,`--no-build-isolation`参数可以解决一些环境下的编译问题。*
第二步:下载预训练模型
在运行工具之前,需要下载两个核心的预训练模型权重文件:一个是GPT-Image-Edit自身的模型,另一个是其依赖的FLUX.1基础模型。
- 安装Hugging Face Hub客户端: 这是一个用于从Hugging Face模型库下载文件的命令行工具。
pip install -U huggingface_hub - 下载模型文件:
- 设置模型保存路径:首先,在你的电脑上创建一个目录用来存放模型文件,例如
my_models,并记住这个路径。 - 下载GPT-Image-Edit模型: 将
${MODEL_PATH}替换为你刚创建的目录路径。huggingface-cli download --resume-download UCSC-VLAA/gpt-image-edit-training --local-dir ${MODEL_PATH} - 下载FLUX.1模型: 将
${FLUX_PATH}替换为你刚创建的目录路径(可以和上面是同一个路径)。huggingface-cli download --resume-download black-forest-labs/FLUX.1-Kontext-dev --local-dir ${FLUX_PATH}
- 设置模型保存路径:首先,在你的电脑上创建一个目录用来存放模型文件,例如
第三步:运行图像编辑工具
项目提供了两种运行方式:命令行界面和Gradio Web界面。Web界面对于普通用户来说更直观、更友好。
方法一:通过Gradio Web界面运行(推荐)
这种方式会启动一个本地网站,你可以在浏览器中上传图片并输入文本指令进行编辑。
- 启动Web服务: 在终端中运行
app.py脚本。请务必将命令中的${MODEL_PATH}和${FLUX_PATH}替换成你在第二步中设置的真实路径。python app.py --model_path /path/to/your/models/final_checkpoint --flux_path /path/to/your/flux_models例如,如果你的模型保存在
/home/user/my_models下,则路径可能分别为/home/user/my_models/final_checkpoint和/home/user/my_models。 - 访问Web界面: 启动成功后,终端会显示一个本地网址,通常是
http://127.0.0.1:7860。在你的浏览器中打开这个地址,即可看到操作界面。 - 如何操作:
- 在界面上,你会找到一个用于上传图片的区域。
- 在图片下方或旁边,会有一个文本框,用于输入你的编辑指令(例如,“把天空换成晚霞”或“移除图片中的路人”)。
- 点击“提交”或类似的按钮,等待模型处理后,界面上就会显示出编辑好的图片。
方法二:通过命令行界面(CLI)运行
这种方式适合自动化处理或在没有图形界面的服务器上运行。
- 运行CLI命令: 同样,需要指定正确的模型路径。
MODEL_PATH="path/to/model/final_checkpoint" FLUX_PATH="path/to/flux" CUDA_VISIBLE_DEVICES=0 python -m univa.serve.cli \ --model_path ${MODEL_PATH} \ --flux_path ${FLUX_PATH}CUDA_VISIBLE_DEVICES=0表示指定使用第一块GPU进行计算。如果你的电脑有多个GPU,可以修改这个数字。 - 交互式输入: 运行后,程序会提示你输入图片路径和编辑指令,处理完成后会输出结果图片的保存路径。
面向开发者的进阶使用:模型训练
如果你是AI研究者或开发者,希望基于自己的数据训练模型,可以参考仓库中提供的训练指南。
- 数据准备:
- 从Hugging Face下载
UCSC-VLAA/GPT-Image-Edit-1.5M数据集。 - 按照项目说明,准备一个
data.txt文件,该文件描述了图像数据和标注文件的路径。
- 从Hugging Face下载
- 准备预训练权重: 训练过程需要FLUX.1和Qwen2.5-VL模型的权重作为起点。你需要先下载这些权重,并运行项目提供的脚本
scripts/make_univa_qwen2p5vl_weight.py将其转换为项目所需的格式。 - 分阶段训练: 训练分为两个阶段,需要分别运行
flux_qwen2p5vl_7b_vlm_stage1_512.sh和flux_qwen2p5vl_7b_vlm_stage2_1024.sh脚本。 这是一个计算密集型过程,需要强大的GPU资源。
应用场景
- 创意设计辅助设计师可以在初步设计稿的基础上,通过文本指令快速迭代,例如“将背景换成森林风格”、“让这个标志更有金属质感”,从而极大提升工作效率。
- 社交媒体内容创作个人用户或社交媒体运营者可以轻松地修改图片,如“移除照片里的游客”、“给我的猫加上一顶生日帽”,让图片内容更有趣、更具吸引力。
- 电子商务商品图优化电商卖家可以使用此工具优化商品图片,例如“把这个T恤衫换成红色”、“让图片背景更干净”,以低成本的方式提升商品展示效果。
- AI科研与学习AI领域的学生和研究人员可以利用这个开源项目和数据集,深入学习和探索多模态模型、指令驱动的图像编辑等前沿技术。
QA
- 这个项目和Midjourney、Stable Diffusion有什么不同?Midjourney和Stable Diffusion主要是根据文本描述从零开始生成一张全新的图片。而GPT-Image-Edit的核心功能是编辑已有的图片,它根据你的文本指令对你提供的图片进行修改,而不是凭空创作。
- 我是否需要很强的编程能力才能使用它?不需要。如果你只是想使用它的编辑功能,只需要按照“使用帮助”中的步骤,通过Gradio Web界面操作即可,这个过程不需要编写任何代码。 只有当你需要自己训练模型时,才需要一定的编程和深度学习知识。
- 运行这个模型对电脑配置有什么要求?运行这个模型,特别是进行推理计算,需要一块性能较好的NVIDIA显卡(GPU),因为它依赖CUDA进行加速。具体的显存需求没有在文档中明确列出,但通常这类模型至少需要8GB以上显存才能流畅运行。模型训练则需要更强大的GPU资源。
- 这个项目是完全免费的吗?是的,项目代码和数据集是开源的,可以免费使用。但需要注意,其依赖的FLUX.1模型权重遵循特定的非商业许可协议(FLUX.1 Kontext [dev] Non-Commercial License),如果你计划用于商业用途,需要仔细阅读并遵守相关许可条款。
- 为什么需要下载两个模型(GPT-Image-Edit和FLUX.1)?GPT-Image-Edit模型是在FLUX.1这个强大的基础模型之上进行微调训练得来的。可以理解为FLUX.1提供了底层的图像理解和生成能力,而GPT-Image-Edit则专注于学习如何根据指令进行更精确的“编辑”任务。因此,运行时两者都需要。